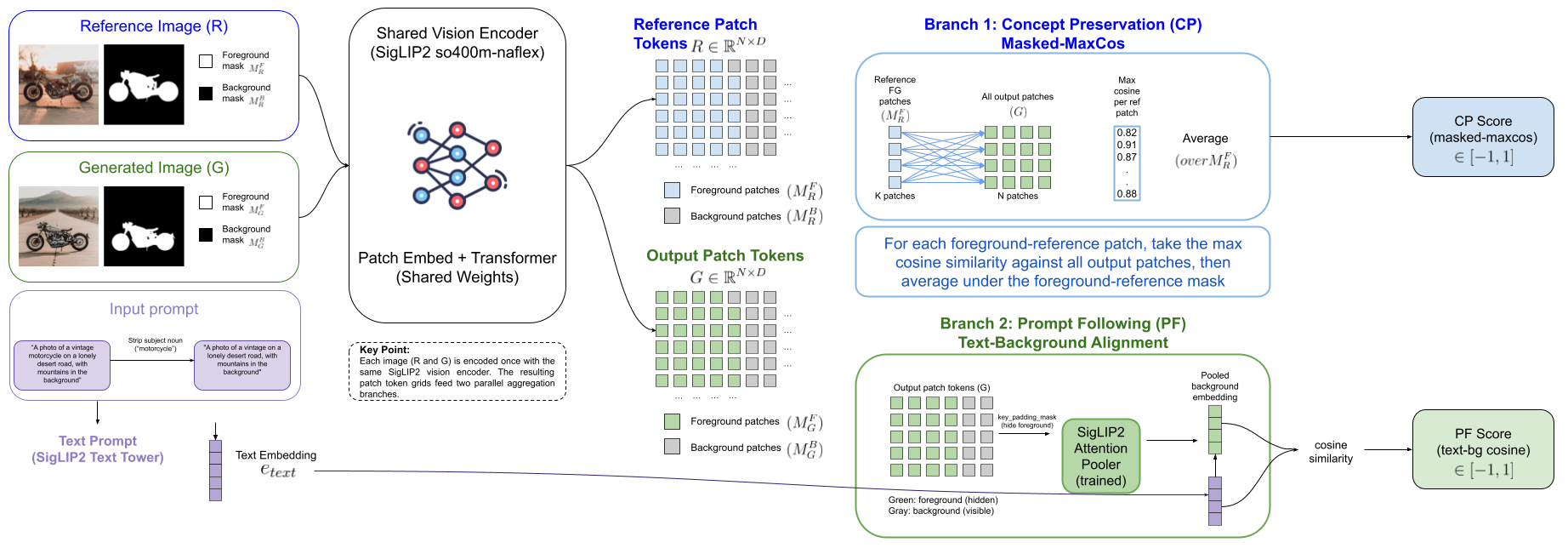
Abstract
Evaluating single-concept personalization in text-to-image diffusion has seen two categories of quantitative metrics: Concept Preservation (CP) measures identity fidelity to a reference while Prompt Following (PF) measures whether the generated scene matches the prompt. Personalization papers have commonly computed these signals using three separate backbones: CLIP-I and DINO for CP, CLIP-T for PF. In this paper, we show that existing metrics fall short of correlating with human perception because they attend to the image as a whole, instead of distinguishing the concept subject from the background. This distinction is important from a human perception point of view as the concept subject in the output image should be very similar to the input concept (CP), whereas the output background should adhere closely to the text prompt (PF). To improve personalization evaluation in this way, we introduce MaSC, a unified metric that attends to CP and PF by differentiating concept subject regions. Specifically, given an externally provided foreground concept mask, MaSC computes the CP and PF scores from a single forward pass of a frozen SigLIP2 encoder per image.
On DreamBench++ human ratings, MaSC reaches Krippendorff α = +0.471 on CP — beating every non-LLM baseline tested (DINOv3, DreamSim, AM-RADIO, DIFT-SDXL, DINO-I, CLIP-I) and GPT-4V, while sitting within Δα = 0.028 of GPT-4o. To distinguish human perception bias we also evaluate our method, as well as common SOTA baselines, on ORIDa, a real-photo benchmark of identity preservation across physical environments. In this experiment MaSC reaches AUC = 0.992 almost perfectly identifying concept subjects. The PF score, obtained by MaSC without a second encoder forward pass, beats the CLIP-T baseline shipped with DreamBench++. In summary, our comprehensive evaluations demonstrate that MaSC establishes a new state-of-the-art for non-LLM concept preservation, while providing an efficient, unified standard for personalization evaluation. We release MaSC as a pip-installable Python package, alongside independent reproductions of every comparator's published numbers.
Acknowledgments
This research was conducted in collaboration with ArtiCollect, who funded the work, contributed to data collection, and provided domain expertise in art.
BibTeX
@misc{bartkowiak2026mascmaskedsimilaritymetric,
title = {MaSC: A Masked Similarity Metric for Evaluating Concept-Driven Generation},
author = {Patryk Bartkowiak and Lennart Petersen and Bartosz Kotrys and Dominik Michels and Sören Pirk and Wojtek Palubicki},
year = {2026},
eprint = {2605.22469},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2605.22469}
}